Hey, my app premade has had issues deploying over the last 24hrs; it’s failing on the migration step and I don’t believe I’ve changed anything in the connection or DB settings since the last successful deployment
==> Release command
Command: /app/bin/premade eval Premade.Release.migrate
Starting instance
Configuring virtual machine
Pulling container image
Unpacking image
Preparing kernel init
Configuring firecracker
Starting virtual machine
Starting init (commit: cc4f071)...
Running: `/app/bin/premade eval Premade.Release.migrate` as nobody
2021/08/03 10:07:37 listening on [fdaa:0:3049:a7b:a98:febd:a5b4:2]:22 (DNS: [fdaa::3]:53)
Reaped child process with pid: 562 and signal: SIGUSR1, core dumped? false
10:07:41.447 [error] Could not create schema migrations table. This error usually happens due to the following:
* The database does not exist
* The "schema_migrations" table, which Ecto uses for managing
migrations, was defined by another library
* There is a deadlock while migrating (such as using concurrent
indexes with a migration_lock)
To fix the first issue, run "mix ecto.create".
To address the second, you can run "mix ecto.drop" followed by
"mix ecto.create". Alternatively you may configure Ecto to use
another table and/or repository for managing migrations:
config :premade, Premade.Repo,
migration_source: "some_other_table_for_schema_migrations",
migration_repo: AnotherRepoForSchemaMigrations
The full error report is shown below.
** (DBConnection.ConnectionError) connection not available and request was dropped from queue after 2977ms. This means requests are coming in and your connection pool cannot serve them fast enough. You can address this by:
1. Ensuring your database is available and that you can connect to it
2. Tracking down slow queries and making sure they are running fast enough
3. Increasing the pool_size (albeit it increases resource consumption)
4. Allowing requests to wait longer by increasing :queue_target and :queue_interval
See DBConnection.start_link/2 for more information
(ecto_sql 3.6.2) lib/ecto/adapters/sql.ex:760: Ecto.Adapters.SQL.raise_sql_call_error/1
(elixir 1.12.2) lib/enum.ex:1582: Enum."-map/2-lists^map/1-0-"/2
(ecto_sql 3.6.2) lib/ecto/adapters/sql.ex:848: Ecto.Adapters.SQL.execute_ddl/4
(ecto_sql 3.6.2) lib/ecto/migrator.ex:645: Ecto.Migrator.verbose_schema_migration/3
(ecto_sql 3.6.2) lib/ecto/migrator.ex:473: Ecto.Migrator.lock_for_migrations/4
(ecto_sql 3.6.2) lib/ecto/migrator.ex:388: Ecto.Migrator.run/4
(ecto_sql 3.6.2) lib/ecto/migrator.ex:146: Ecto.Migrator.with_repo/3
(premade 0.1.0) lib/release.ex:12: anonymous fn/2 in Premade.Release.migrate/0
Main child exited normally with code: 1
Reaped child process with pid: 564 and signal: SIGUSR1, core dumped? false
Starting clean up.
Error Release command failed, deployment aborted
I thought for some reason the pool_size might not be big enough (although I shouldn’t be receiving any traffic other than spam bots), so I even scaled down the app to 0 to just get a deployment out but this is still occurring
I can see the DB details are there in secrets still.
Can you see if I’m doing anything silly? The DB is on premade-db
Hm so not sure what happened to take up all of the connections; but turns out deploying doesn’t work if the scale is set to 0… So I scaled it back to 1, deployed while connections weren’t used and so far so good. Hopefully upping the pool_size will help
What was your pool size set to? The migration step runs as an entirely different VM so it shouldn’t matter what that’s set to, really, as long as postgres has RAM and connection slots.
No worries, I’m not receiving much traffic so I didn’t mind the downtime just yet. My pool_size was set to the default 10; upped it to 20. Good to know migrations shouldn’t be using that though, but then that makes this even weirder.
I’ve had this once before on Gigalixir, but they were limiting to 2 connections and I suspect Oban ate them up.
I checked RAM usage at the time and didn’t see anything out of ordinary either. Mystery!
@kurt this is still happening - when deploying from CI (GitHub Actions) I’m getting
==> Release command
Command: /app/bin/premade eval Premade.Release.migrate
Starting instance
Configuring virtual machine
Pulling container image
Unpacking image
Preparing kernel init
Configuring firecracker
Starting virtual machine
Starting init (commit: cc4f071)...
Running: `/app/bin/premade eval Premade.Release.migrate` as nobody
2021/08/08 12:57:20 listening on [fdaa:0:3049:a7b:a98:9566:4f9e:2]:22 (DNS: [fdaa::3]:53)
Reaped child process with pid: 562 and signal: SIGUSR1, core dumped? false
Error: :24.459 [error] Could not create schema migrations table. This error usually happens due to the following:
* The database does not exist
* The "schema_migrations" table, which Ecto uses for managing
migrations, was defined by another library
* There is a deadlock while migrating (such as using concurrent
indexes with a migration_lock)
To fix the first issue, run "mix ecto.create".
To address the second, you can run "mix ecto.drop" followed by
"mix ecto.create". Alternatively you may configure Ecto to use
another table and/or repository for managing migrations:
config :premade, Premade.Repo,
migration_source: "some_other_table_for_schema_migrations",
migration_repo: AnotherRepoForSchemaMigrations
The full error report is shown below.
** (DBConnection.ConnectionError) connection not available and request was dropped from queue after 2977ms. This means requests are coming in and your connection pool cannot serve them fast enough. You can address this by:
1. Ensuring your database is available and that you can connect to it
2. Tracking down slow queries and making sure they are running fast enough
3. Increasing the pool_size (albeit it increases resource consumption)
4. Allowing requests to wait longer by increasing :queue_target and :queue_interval
See DBConnection.start_link/2 for more information
(ecto_sql 3.6.2) lib/ecto/adapters/sql.ex:760: Ecto.Adapters.SQL.raise_sql_call_error/1
(elixir 1.12.2) lib/enum.ex:1582: Enum."-map/2-lists^map/1-0-"/2
(ecto_sql 3.6.2) lib/ecto/adapters/sql.ex:848: Ecto.Adapters.SQL.execute_ddl/4
(ecto_sql 3.6.2) lib/ecto/migrator.ex:645: Ecto.Migrator.verbose_schema_migration/3
(ecto_sql 3.6.2) lib/ecto/migrator.ex:473: Ecto.Migrator.lock_for_migrations/4
(ecto_sql 3.6.2) lib/ecto/migrator.ex:388: Ecto.Migrator.run/4
(ecto_sql 3.6.2) lib/ecto/migrator.ex:146: Ecto.Migrator.with_repo/3
(premade 0.1.0) lib/release.ex:12: anonymous fn/2 in Premade.Release.migrate/0
Main child exited normally with code: 1
Reaped child process with pid: 564 and signal: SIGUSR1, core dumped? false
Starting clean up.
Error Release command failed, deployment aborted
Any thoughts? I’m not receiving any traffic and pool_size is 20 now… Postgres app is on premade-db
@kurt@jerome we are also unable to connect to attached DB from app on our staging app ([org-name]-api-v2 - attached to [org-name]-db) after a long time running with no issues. Is there any systemic issue present?
That check is saying it can’t connect to the (local) proxy instance, which probably explains your connection failure. When the new instance starts it may clear up.
Okay, looks like that fixed it. The timing was very poor though, was just demo-ing smth to potential investors when it failed, heh. Demo gods were not on our side today.
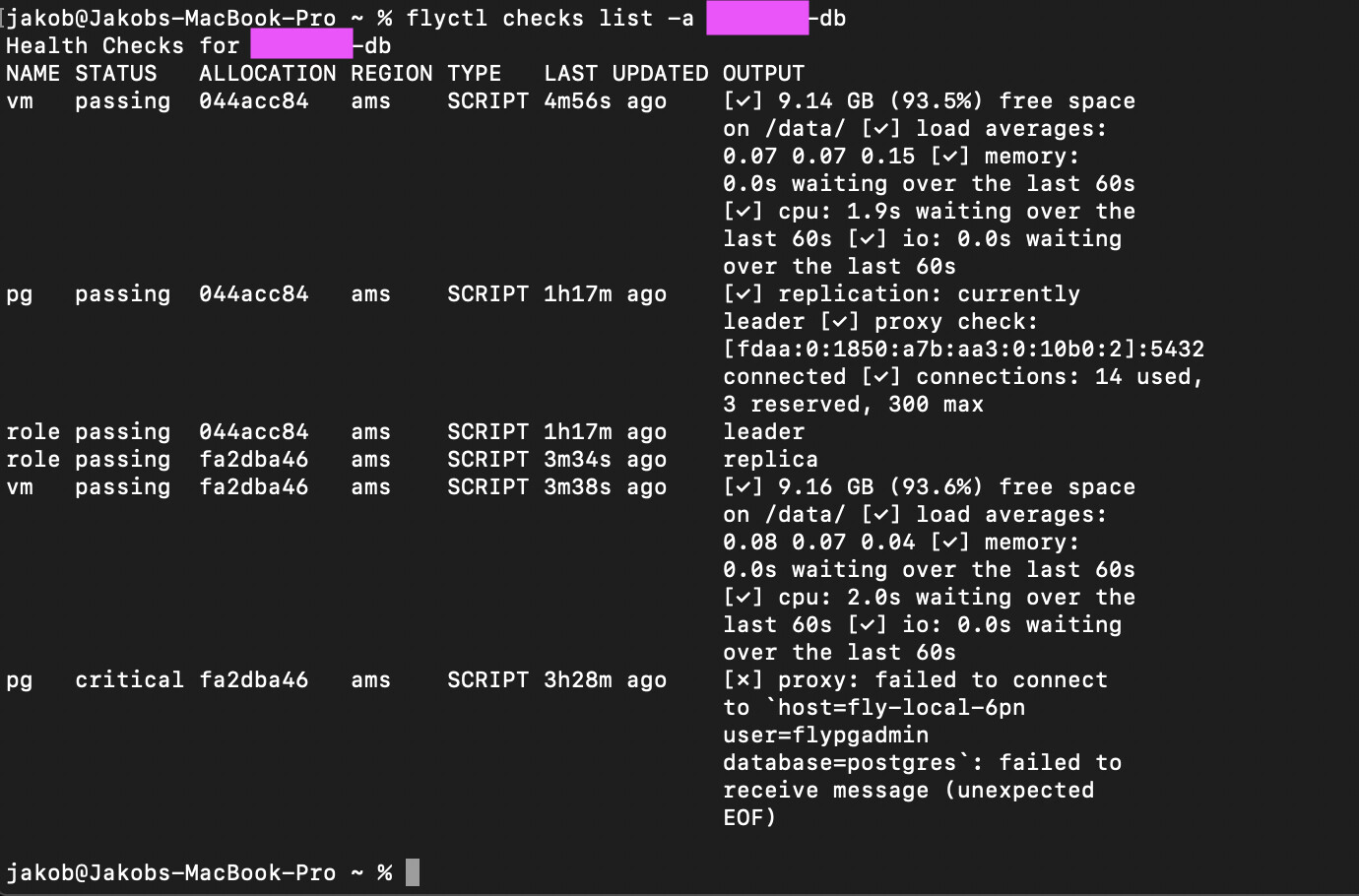
@kurt having DB issues again - connections are dropping, this is with no deployment in the last 19hrs and fairly minimal usage (although trying to go to real users now so it’s not great…)
status reports:
App
Name = premade-db
Owner = premade
Version = 0
Status = running
Hostname = premade-db.fly.dev
Instances
ID VERSION REGION DESIRED STATUS HEALTH CHECKS RESTARTS CREATED
4b29025a 0 lhr run running (leader) 3 total, 2 passing, 1 critical 0 2021-08-17T02:34:49Z
21cf776b 0 lhr run running (replica) 3 total, 2 passing, 1 critical 0 2021-08-17T02:33:48Z
fly checks list --app premade-db
Health Checks for premade-db
NAME STATUS ALLOCATION REGION TYPE LAST UPDATED OUTPUT
vm passing 21cf776b lhr SCRIPT 2m50s ago [✓] 9.13 GB (93.4%) free space
on /data/ [✓] load averages:
0.08 0.13 0.23 [✓] memory:
0.0s waiting over the last 60s
[✓] cpu: 1.1s waiting over the
last 60s [✓] io: 0.0s waiting
over the last 60s
role passing 21cf776b lhr SCRIPT 2h50m ago replica
pg critical 21cf776b lhr SCRIPT 2h50m ago [✗] proxy: context deadline
exceeded
vm passing 4b29025a lhr SCRIPT 8s ago [✓] 9.12 GB (93.2%) free space
on /data/ [✓] load averages:
0.00 0.02 0.01 [✓] memory:
0.0s waiting over the last 60s
[✓] cpu: 1.0s waiting over the
last 60s [✓] io: 0.0s waiting
over the last 60s
role passing 4b29025a lhr SCRIPT 2h46m ago leader
pg critical 4b29025a lhr SCRIPT 2h46m ago [✗] proxy: context deadline
exceeded
That proxy health check is basically the problem, it’s not accepting connections.
If you look at fly logs you might see some errors connecting to Consul. The Stolon proxy doesn’t handle these kinds of errors well and won’t recover. We’ve been hesitant to automatically restart databases but the fix is to stop the VM(s) with that error and see if health checks start passing.
We have some improvements to the postgres app coming soon that seem to help with this problem.
One thing you can look into is connecting to the Postgres nodes directly and bypassing the proxy. Getting DB drivers to do this takes a little work, but it would keep you functional when this problem rears its head.
Most drivers need you to build a connection string like this:
Those are made up IPs, you’ll want to replace the addresses with whatever is in fly ips private -a premade-db.
The target_session_attrs is a libpq option that tells the driver to connect to both and use the one that’s writable. It works exceptionally well if the driver implements it. If we could figure out how to get all apps to connect this way, we’d drop the proxy (which is really just there for convenience).
Do you still suggest I use the direct connection to the private IPs as per your example? Just tried it out and it works. Are these private ips not going to change?
If you add and remove volumes, those private IPs will change. Or if we migrate your volumes (you’ll be notified if this happens). But that’s the only time they’ll change.
If your db library handles finding the writable node correctly, and you’re ok updating your connection string when your database cluster changes, it’s the best way to connect.