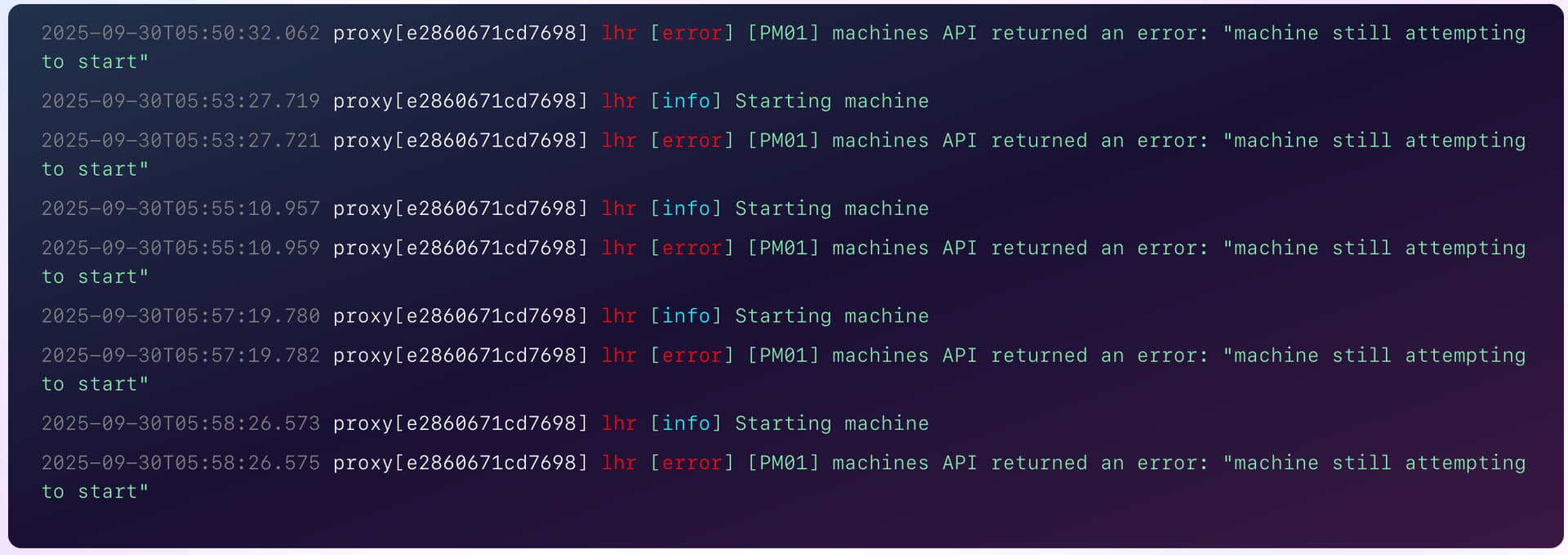
For months — across multiple apps, machines, and regions — I eventually see machines reach a state in which they fail to resume from suspended states with the following message:
[error] [PM01] machines API returned an error: “machine still attempting to start”
There is no further information, and the only fix is to scale to zero to remove the dead machines and then scale back up again afterward. I see multiple reports of the same problem throughout this forum, not one of which is answered.
I have seen it on both Astro web server apps and Node.js API apps — seemingly very little in common. It only seems to start occurring after I leave the app alone (no new deployments) for some time, although once it’s started to happen on a machine, redeploying does not fix it, only scaling down and back up does. These apps are all very low traffic and have suspension enabled, which indicates to me that repeated suspend/resume cycles eventually trigger a bug in Fly’s systems which permanently breaks resume functionality. I have observed the behavior on both single-machine and multi-machine deployments: one by one the machines bite the dust until they’re all dead and I have to manually intervene. Other than that, I have no idea, because no other errors are ever logged.
Anyone else have an idea about this or have found a resolution to it? I’ve been really happy with every other aspect of Fly, but this issue (which just occurred again today on a brand new app that is only 6 days old) has me about at the end of my rope.