Thanks for the info, Daniel, it’s very helpful. I did have limits set, but apparently too high:
[http_service.concurrency]
type = 'requests'
hard_limit = 500
soft_limit = 400
Limiting the request rate via “hey -c” down to 20, 10 and 5 req/s does yield a much better histogram without the slow outliers, with 15 being the sweet spot as far as maxing the req/s with minimal slow requests.
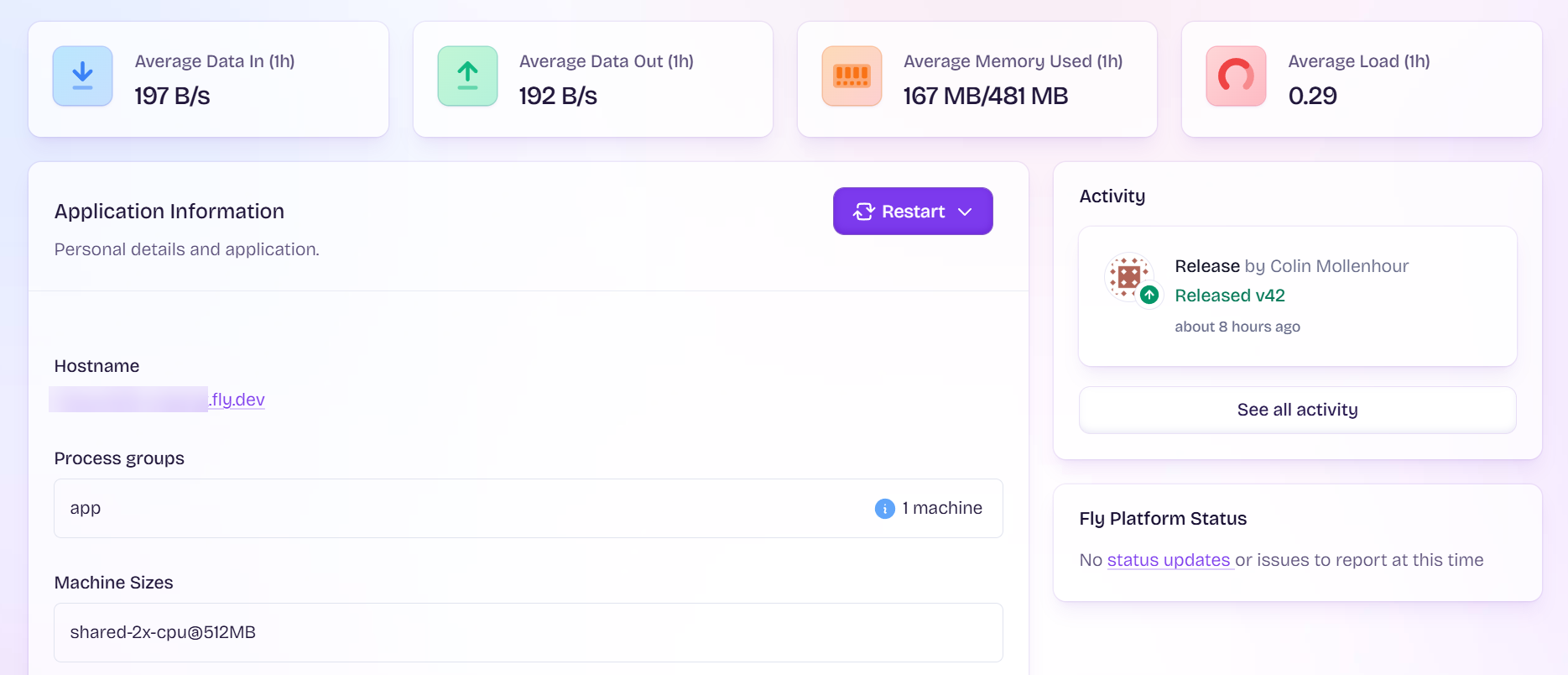
Regarding memory, though, my machine size is and has been ‘shared-cpu-2x@512MB’ and as you can see in the screenshot, it’s using 167MB at idle. I’m testing against the health-check route which doesn’t do much, just a “SELECT 1” on SQLite and fetching a single key on Tigris. I’ve setup a separate monitor now that doesn’t do the Tigris check and also disabled Tigris for load testing to eliminate that as a possible factor. So now overall the app is doing hardly more than “Hello world”. Removing the Tigris check gets the Fly app from ~35-45req/s with Tigris to ~55-60req/s at 15 to 200 concurrency. I’m sure network bandwidth could play a small part, but I’m testing with a 1Gbps uplink and the request/response are just a little over 100 bytes so I think it is negligible as far as impacting req/s.
Running on my PC, I get ~1864req/s at 50 concurrency and ~5684req/s at 500 concurrency with no memory limit. At 500 concurrency with 50,000 requests, monitoring with docker stats, it climbed to 240MB of RAM before the test ended. I used “docker run -m 512M” to emulate the 512MB limit of the Fly machine and I still got ~4663req/s with zero failures. I dropped it to just 128M and I still got ~4411 with zero failures. The Fly machine is running Litestream which in my tests seems to consume only about 16M of RAM at idle (my tests are read-only so don’t write to the WAL). I think this pretty conclusively proves that while it does perform slightly better with more memory, the app is not severely memory starved at a 512MB VM size.
Next, I used the ‘–cpus’ option of Docker to limit CPU, keeping memory limit at 256M to be fair. My PC’s CPU is an Intel i7-12700KF. At 0.5 CPUs I got 1865 req/s with a 0.16% failure rate (84 of 50,000 - still 500 concurrency). In order to get in the 50-60 requests per second ballpark on my PC I had to use “–cpus 0.03”! That’s pretty shocking..
I hate to be negative on your forums, but I was not expecting a ‘shared-cpu-2x@512MB’ CPU to perform on par with “–cpus 0.03” on my local PC. The ‘performance’ class CPUs may be 10x faster, but it brings you into a completely different pricing tier that is in the realm of low-end dedicated servers.
Again, I’ll be the first to admit that running a single machine is not what Fly is engineered to be best at. In my case, I was hoping to run some microservices that used a SQLite database with Litestream continuous backup to avoid the complexities of horizontal scaling and database replication or building logic into my app for fly-replay. Fly can certainly still do that, and I love the simplicity and the CLI and the ecosystem, but the CPU performance is definitely causing me some concern. Given the single-node design, I can’t auto-scale this app and have to scale it vertically, so unless I scale to zero often, the cost of running a machine large enough to handle the peak load all of the time is a lot higher than anticipated.
As far as what the outages looked like, they were pretty much all 503 errors with 15-16 second response times. My app does not return 503 responses for the health check endpoint under any circumstance. Here is an example response header for a failed request:
HTTP/2 503
server: Fly/a608e03f9 (2025-07-10)
via: 2 fly.io
fly-request-id: 01JZXFNEGKYAG4SYVVQ8V4KTVF-dfw
date: Fri, 11 Jul 2025 19:34:00 GMT
Response timing:
Redirect count 0
Name lookup time 2.5e-05
Connect time 0.001253
Pre-transfer time 0.047721
Start-transfer time 15.461976
App connect time 0.047481
Redirect time 0.0
Total time 15.656464
Response code 503
Return keyword ok
Note, this is a “staging” app so it receives zero traffic other than the health checks every 3 minutes (unless it’s getting hit by a bot which could be the case - I’ll try to confirm that next time via the logs).
Thanks for your help!