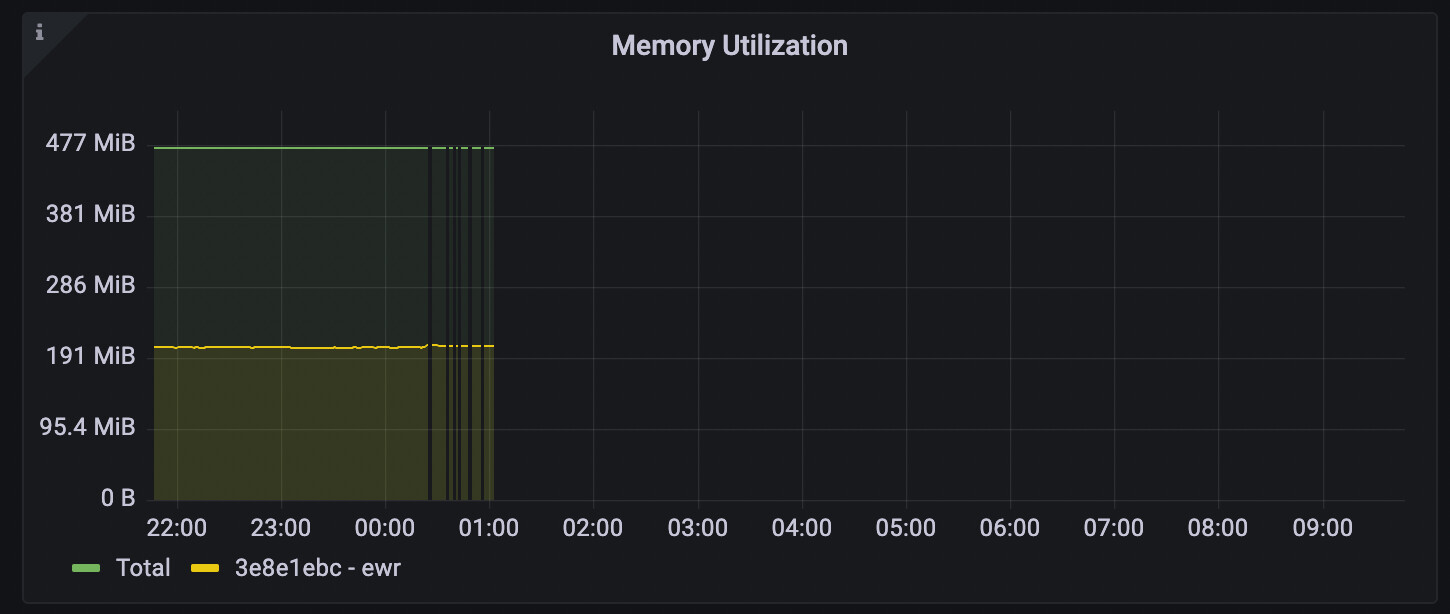
I’ve got an app running in EWR (instance ID 3e8e1ebc) which isn’t responding to any requests. The VM appears to have just…disappeared last night. Here’s the fly_instance_memory_mem_total chart - all the graphs (both reported by my apps and fly.io reported) fall off at 01:03:15am EST
Instance
ID = 3e8e1ebc
Process = app
Version = 52
Region = ewr
Desired = stop
Status = failed
Health Checks = 1 total, 1 passing
Restarts = 1
Created = 2022-10-26T16:16:52Z
Events
TIMESTAMP TYPE MESSAGE
2022-10-26T16:16:42Z Received Task received by client
2022-10-26T16:16:42Z Task Setup Building Task Directory
2022-10-26T16:16:44Z Started Task started by client
2022-10-28T05:03:28Z Task hook failed logmon: Unrecognized remote plugin message:
This usually means that the plugin is either invalid or simply
needs to be recompiled to support the latest protocol.
2022-10-28T05:03:28Z Restarting Task restarting in 1.073728869s
2022-10-28T05:03:32Z Killing Vault: failed to derive vault token: DeriveVaultToken RPC failed: no servers
2022-10-28T05:03:35Z Template Missing: vault.read(apps/data/381214/537454), vault.read(apps/data/381214/537878), vault.read(apps/data/381214/542303), and 2 more
2022-10-28T05:08:40Z Killing Template failed: vault.read(apps/data/381214/537878): vault.read(apps/data/381214/537878): Error making API request.
URL: GET https://active.vault.service.consul:8200/v1/apps/data/381214/537878
Code: 400. Errors:
* missing client token
2022-10-28T05:10:32Z Terminated plugin is shut down
2022-10-28T09:34:50Z Killing Sent interrupt. Waiting 5s before force killing
Checks
ID SERVICE STATE OUTPUT
3df2415693844068640885b45074b954 tcp-8080 passing TCP connect <IP>:8080: Success
According to my monitoring (and my Prometheus telemetry), today’s outage had wider impact than just deployments as described here. My app’s full outage lasted ~20 minutes starting around 5:10am PT.
The pending deployments have cleared and I’m running again as of 11:43 (moved to IAD). Would love to get a follow up on this from Fly, as the VM dying seems completely out of scope of the incident on the status page.
You could also try fly status --all to see if that reveals why.
If it ignores the request from outside and stays running, er … maybe try fly ssh console to SSH into that instance. And then type shutdown (or if needed sudo shudown). That should shut it down from within. Depending on your scaling settings etc, you may get a new one added in its place. However you can deal with that after.