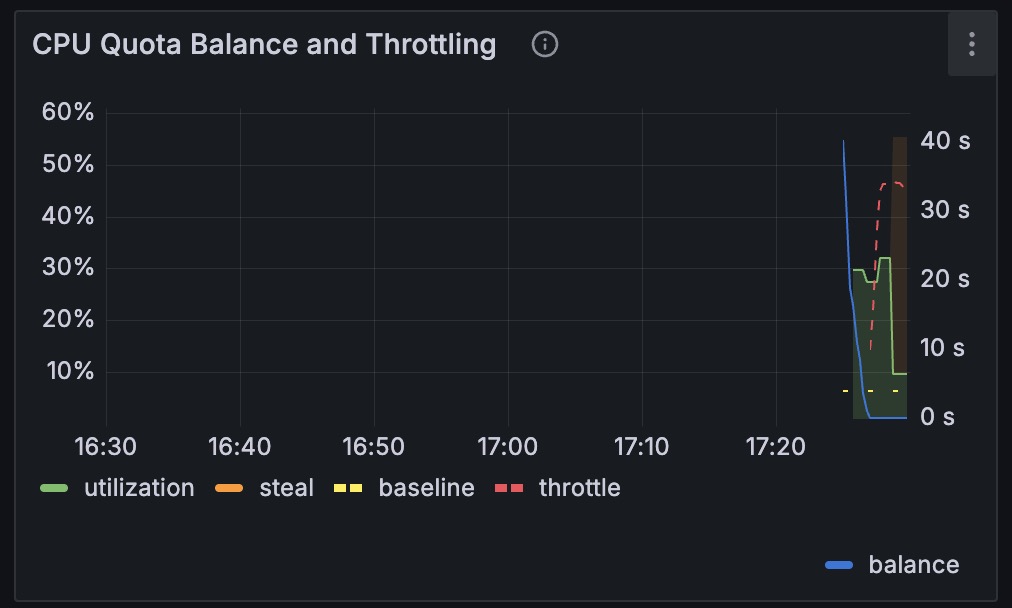
We’re still operating a small-scale service, so our production database runs on shared-cpu-2x.
When I run fly pg backup restore in this state, the restore process never completes because it times out before finishing, as shown below:
2025-09-26T08:35:43Z app[0802d76a3554d8] nrt [info]panic: failed to handle remote restore: failed to monitor recovery mode: timed out waiting for PG to exit recovery mode
2025-09-26T08:35:43Z app[0802d76a3554d8] nrt [info]goroutine 1 [running]:
2025-09-26T08:35:43Z app[0802d76a3554d8] nrt [info]main.panicHandler({0xa0d180, 0xc00018a0b0})
2025-09-26T08:35:43Z app[0802d76a3554d8] nrt [info] /go/src/github.com/fly-apps/fly-postgres/cmd/start/main.go:190 +0x4a
2025-09-26T08:35:43Z app[0802d76a3554d8] nrt [info]main.main()
2025-09-26T08:35:43Z app[0802d76a3554d8] nrt [info] /go/src/github.com/fly-apps/fly-postgres/cmd/start/main.go:67 +0xe65
2025-09-26T08:35:43Z app[0802d76a3554d8] nrt [info] INFO Main child exited normally with code: 2
Because the restore VM defaults to the same shared-cpu-2x class, it quickly gets throttled during WAL replay.
It would be very helpful if we could specify --vm-size (for example, performance-1x) when invoking fly pg backup restore, so that restores can run on a more powerful instance without being constrained by the production VM’s size.