If this is the case, reach out directly and we’ll work through options. We have knobs we can turn. We’ll get you through this. The fleetwide change is non-optional; as you saw with the preceding comment, it’s causing problems for customers. But if we’re putting you in a bind, we’ll figure a way through it with you.
Thanks. We wrote in earlier but got a negative response, I’ll write in again.
If we can just push back any changes to 12 Nov it just means I don’t have to try and get the team to turn on a dime.
I talked to support and it sounds like we’ve got this worked out with your case. I write this here to note for others that if we’ve put you in a bind, we have levers to turn and knobs to pull. I’ve made sure the support engineers (who rule) know there are escalation paths here too.
We really don’t want anybody panicking and paying us a bunch more. If we roll this out correctly, I’m optimistic that almost nobody should notice it happening (except that the platform will be more stable). There are maybe a few apps running here that have really leaned in to the idea that their shared-1x got them a whole core, and we’ll have to talk through those cases, but in no case should there be scary time pressure.
The messaging here is consistent that less than 1% of all customers got the email or very few apps must see any degradation. It follows that the impact these few apps / customers must have on other apps must also be negligible?
Why not then use the lever to extend the enforcement for much later?
Appreciate it isn’t a case of wanting to bill more but if this change must be enforced right away, wish there was a knob where I could tell Fly to never throttle and bill me on the extra CPU use but serve all my requests (the RAM is limited, so I imagine apps on shared-1x would die sooner or later running out of memory). Someone noted that this is something Fly considered but dismissed. Wish Fly revisit this, if it is engineering-wise tractable.
(I’m mostly in favour of this change, btw; but not in a way that does so on short notice).
The problem isn’t the platform is consistently overutilized. It’s not, not even close. The problem is that people on shared core Fly Machines are always just one big performance deploy from somebody else away from randomly getting ratcheted back to the 1/16th of a core they provisioned. It’s the randomness that’s the problem. You saw it described upthread as a “brownout”; that’s the user experience.
It’s not happening fleetwide, or even region-wide; it’s happening on particular worker servers. It’s unacceptable to us, and we’re fixing it.
We’re considering a bunch of alternative scheduling/pricing plans medium term, and aren’t ruling anything out, but the status quo is bothering people, so we’re not waiting on ambitious stuff before rolling this out.
Again: thoughts welcome on other things we can do to relieve the stress this is causing for some of you.
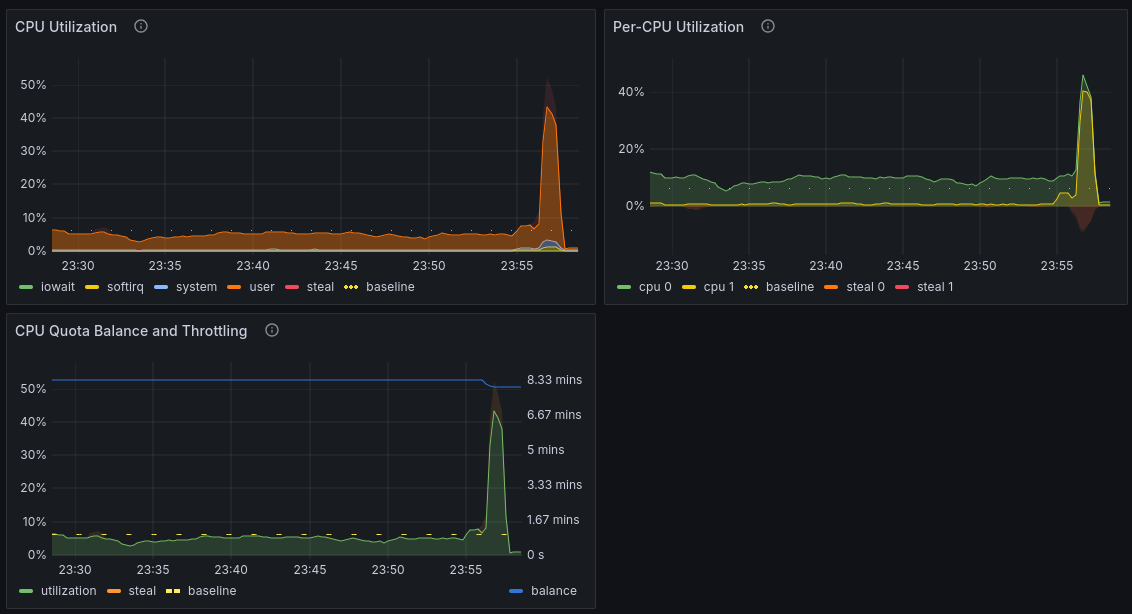
I got this email stating shared-1x - throttled for 24.0h which was surprising because I expected the machine to be doing nothing most of the time. Checking the Fly Instance graphs, I see:
It looks like the 15% utilization is /.fly/hallpass, which seems out of my control? I am not sure if I am reading the situation correctly. I could not find much more information about what hallpass does, so any pointers would be helpful.
Thanks for letting us know about this. It’s unexpected for hallpass to be using as much CPU/memory as it is in your machines. I reached out via email to discuss debugging this.
Thanks for bringing this up to Fly’s attention. I originally though the hallpass memory usage was because I has ssh’d into the machine. I didn’t realize it was consuming 10MB+ on its own.
It’s the former. I’ll keep saying this until it sticks: we are not searching for Fly Machines using “too much” CPU and penalizing them. That’s not how any of this works. We do not want you to avoid redlining your Fly Machines. Use as much CPU as you want. But we’re making burst more predictable than it is today, when you can lose all your burst capability instantly when a large, high-priority job is deployed to the same physical.
Ben will have more to say about this, but we’ve been investigating this, and in at least one of the cases we’re looking at, the problem here is that hallpass was getting env vars from the customer application, which included Golang GC parameters. We’ll address that, but for obvious reasons that isn’t going to hit most users.
We’ve decided to give performance vCPUs a 100% CPU quota. This is more consistent with what folks expect when they hear “performance” and is more consistent with the pricing difference between shared and performance vCPUS.