evening guys, i received email this afternoon. there are a lot of questions in my brain, i hope someone here can help me clarify these. Thanks in advance.
I have 2 apps 3 machines:
- App A (2 machines)
- App B (1 machine)
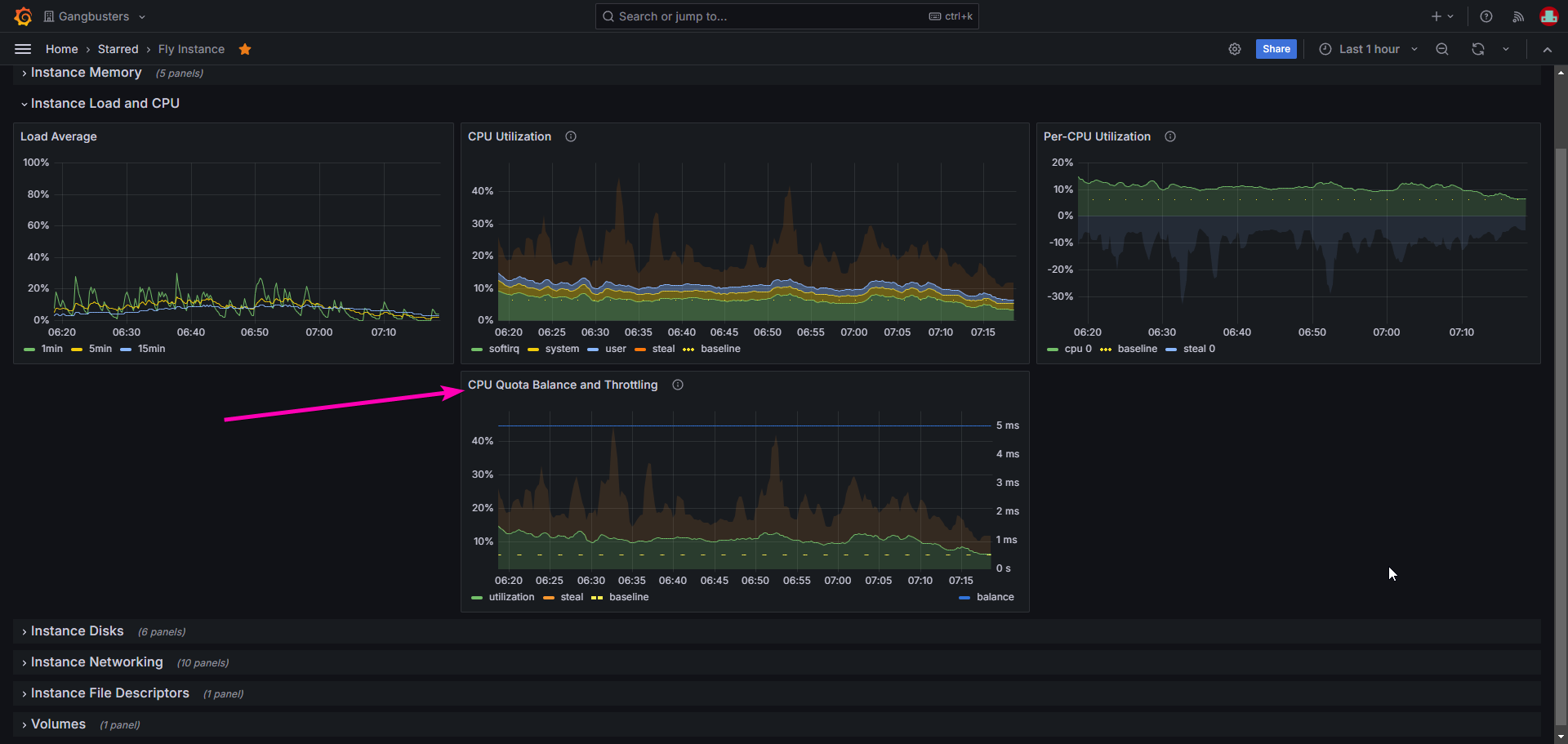
below image is App A (2 machines)

looking at image above,
- i assume it is under utilised, i mean giving it too much CPU power. right? does that means, i don’t have to worry about being throttled?
- or it means otherwise? looking at the quota balance, the utilisation only has that much left.
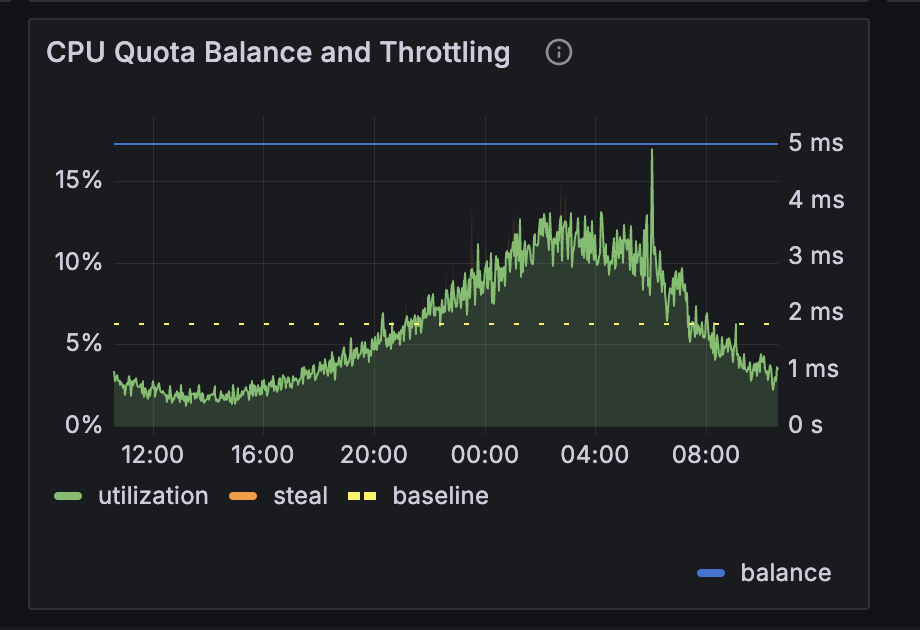
Below image is App B (1 machine), this is the machine i received warning email.

- from the cpu utilisation, i can see high utilization, it is around 20%.
- The CPU quota is confusing to me, looking at the chart, the balance is at 5ms there, does that means the quota is used up or still 100% available?
- or, the sharp drop means throttled?
am sorry for those dummy questions, i am quite beginner in flyio machine things and i didn’t catch up well, flyio innovate and moves fast.
and 1 last question,
- The “throttled” means the machine will be down and paused for the throttled duration or it slows down to certain level? am confused.
thanks in advance guys.